set 包含的 cache line 行数不同,cache 会被分为不同的类
注意:这句话不是说,一个 cache 里的 set,可能有多种行的组合,比如 set 0 有两行,set 1 有 4 行,而是,这个 cache 中的所有 set 每个 1 行,这个 cache 被分为一类,另一个 cache 中的所有 set 每个 4 行,被分为另一类
直接映射
将 E=1 的 cache 称之为直接映射,也就是每个 set 只有一个 cache line
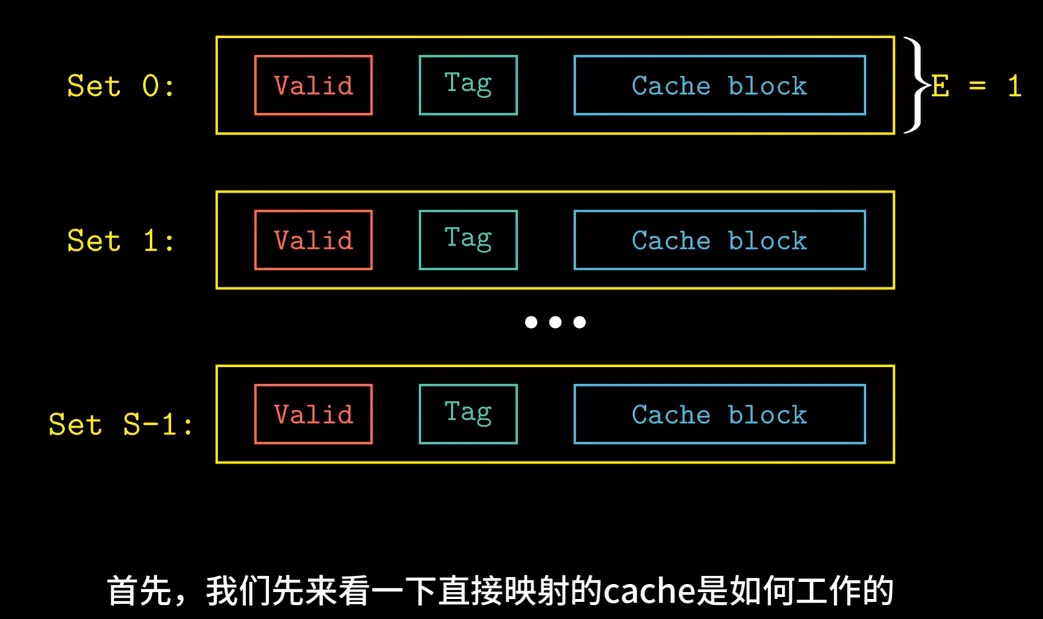
假设的模型:
一个 cpu 一个寄存器一个 L 1 和一个内存
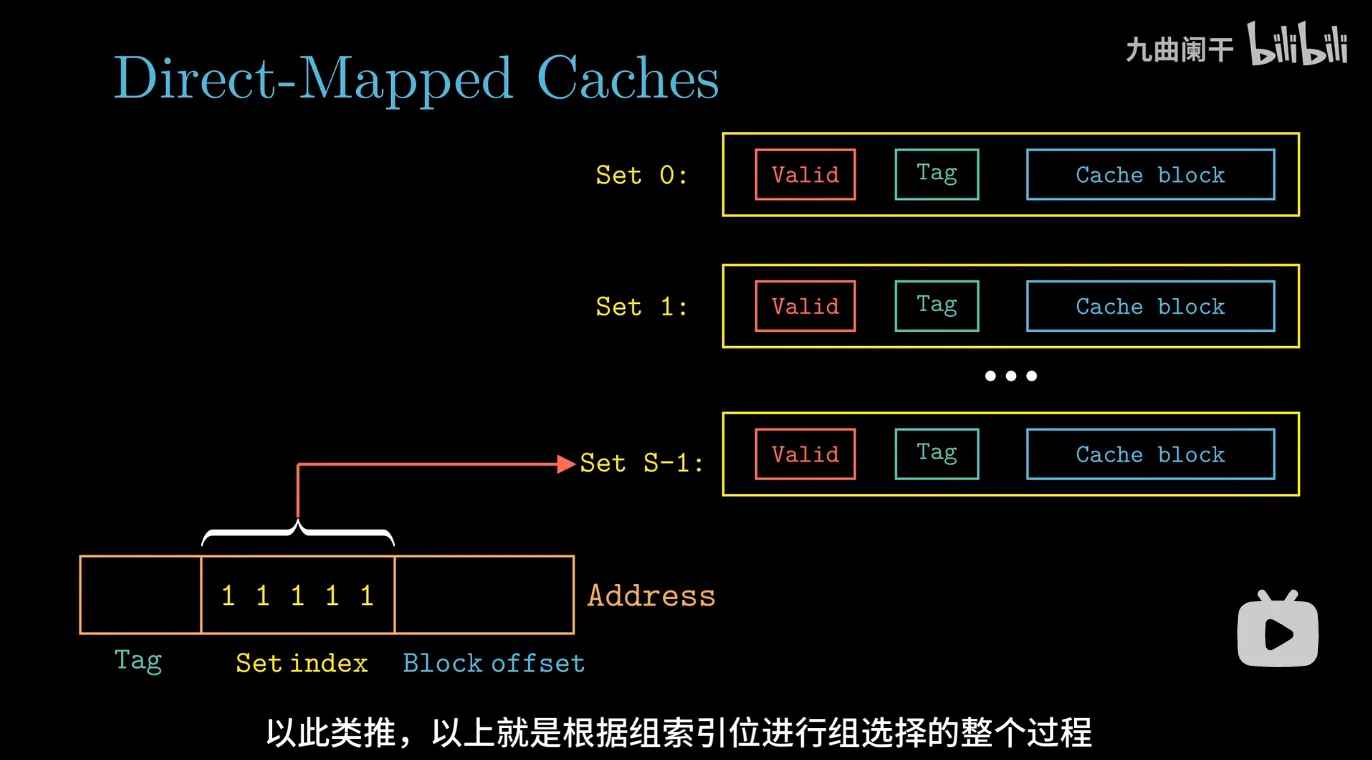
set Index 组索引位
确定这个目标数据属于哪个 set

这里的组索引位的长度是 5,这些二进制位被解释乘一个无符号数
这里的 5 就是
如何进行的检索:
当 s 为 0 时,选择的结果是 set 0
set index 是二进制表示的数,它的十进制结果就是对应的第几个

最大的 11111 也就是最后一个
确定了组以后,就要开始进行 line(行)匹配
-
确认 cache line 的地址标记为和我们要搜的地址是否一致
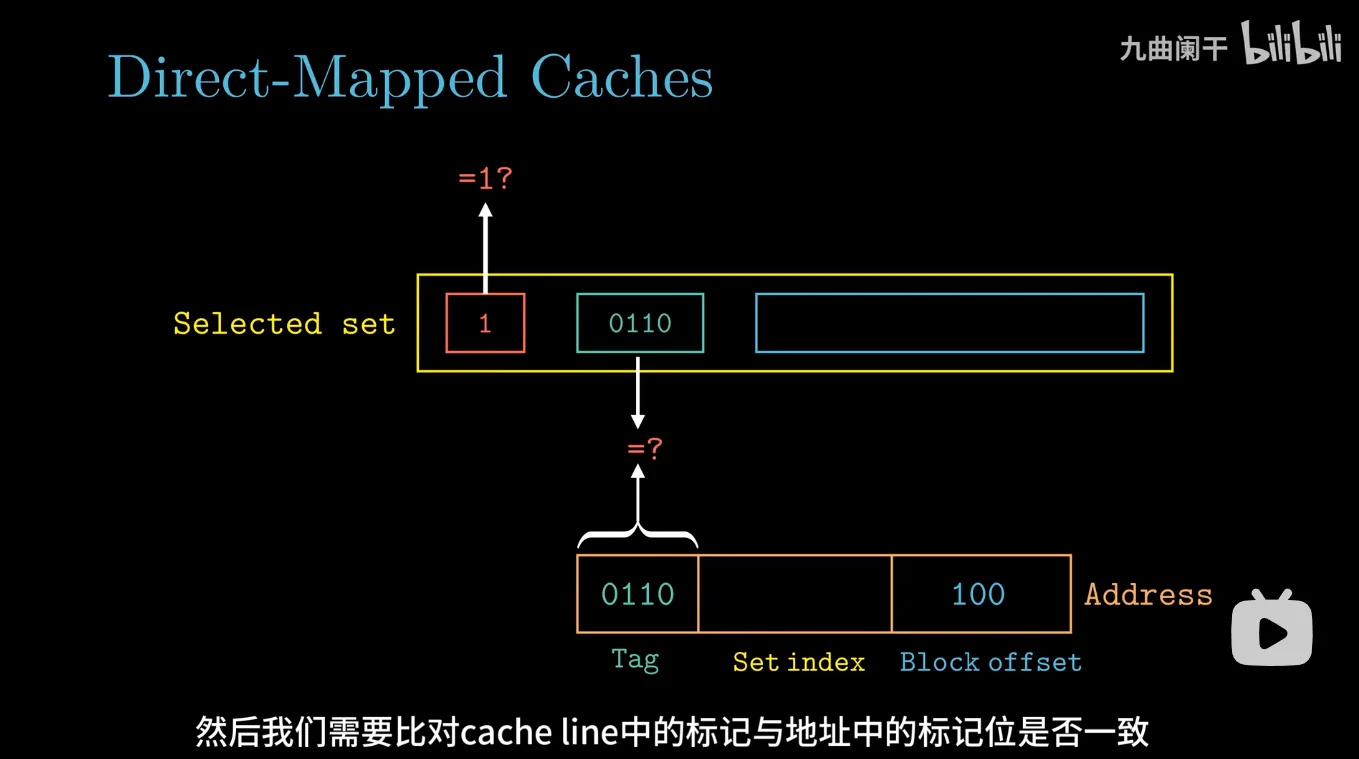
图中这里中间的 set index 已经用过了,所以不标了,用了 set index 后就该用 tag 了 -
如果一致,表示目标数据一定在当前的 cache line 中,如果不一致,或者有效位为 0,说明目标数据不在当前的 cache line 中
-
字抽取,使用 block offset,根据偏移量确定目标数据的确切位置,图中数据块的大小为 8 个字节,当 block offset 为 100,也就是
也就是 4,从第四个位置后开始算
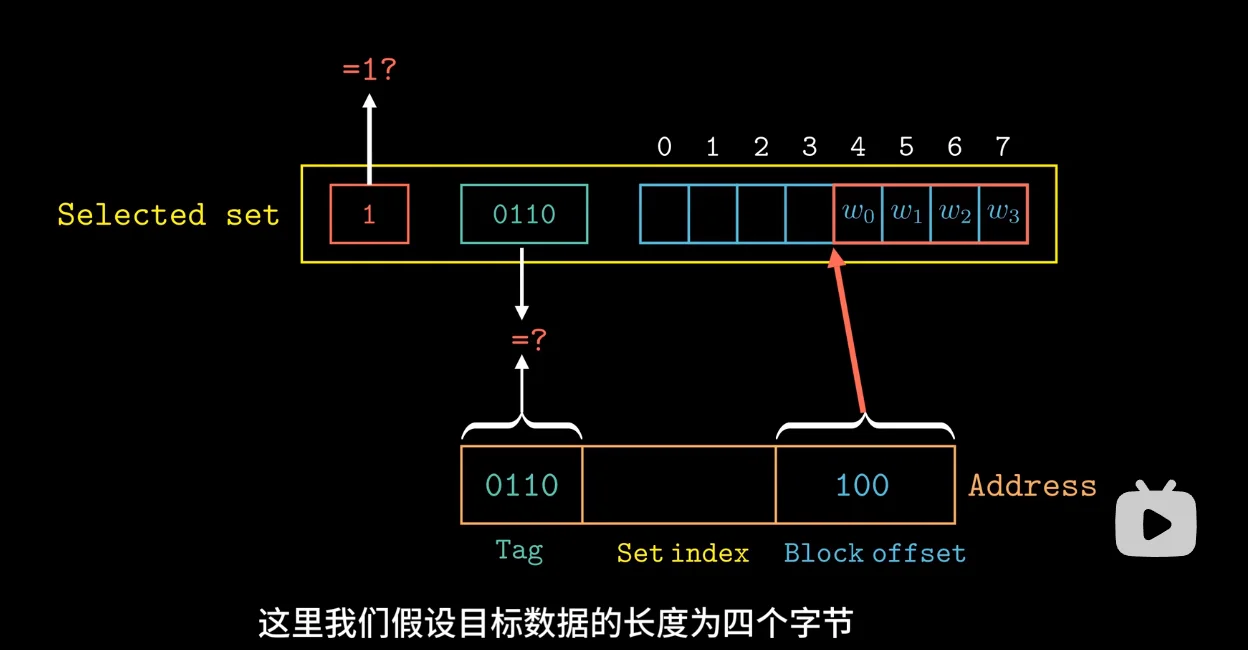
现在就通过目标地址,找到了目标数据,我们就可以获取到目标数据的副本了
如果发生了不命中,那么 cache 需要从存储器层级结构的下一层取出被请求的块
具体例子
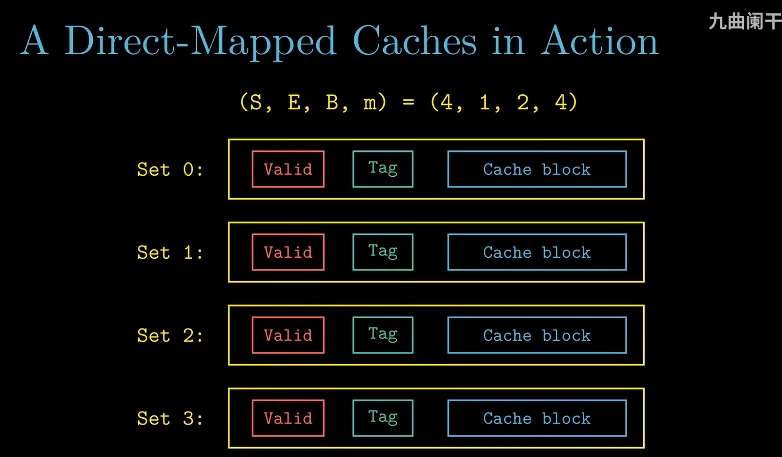
在这个例子中,m 为 4,这个 m,表示我们的一个 line 是 4 位的,有 16 个字节,这 16 个字节可能被表示为 M=16 给出
看下面这个图,就说明了这个问题,1 行包括 tag index 和 offset,这里一共是 4 个数,也就是 4 位的
地址空间可以用编号 0~15 来表示,因为 4 位 2 进制最大是 1111,也就是 15
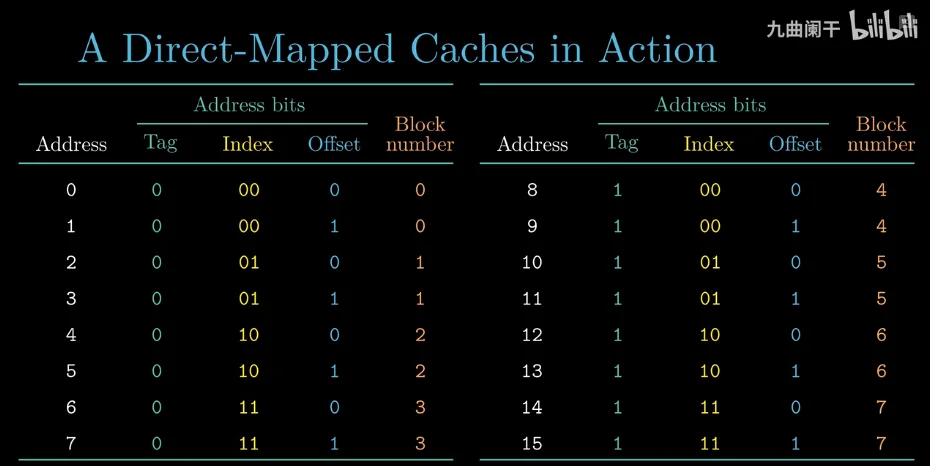
每一个内存块依靠标记位和索引位共同作用, 唯一确认
每个地址块包含两个字节(为什么?)
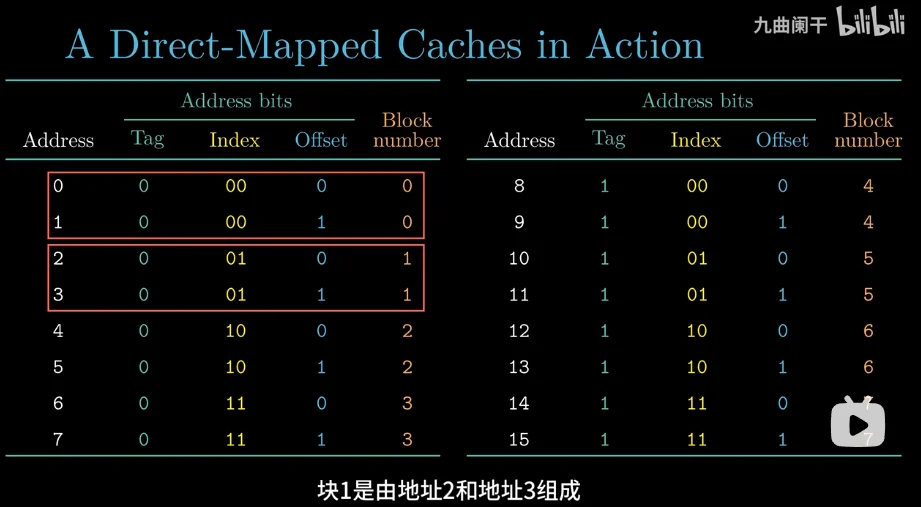
因为这里的
上面我这个是错误言论,具体看视频
这里只有 4 个 set,有两个内存块映射到同一个 set 的情况,上面这个图好像是内存中存储图,现在说的是,内存到 cache 的映射
如何自己计算 s t b 各有多少位
考试的时候给这个, 也就是字地址

给地址的总长度为 16 字节,有 8 组, b 这里这个位给的是 64 B