好的,我们用一个生产车间的场景来生动形象地记忆单缓冲区和双缓冲区的数据处理用时公式。
场景设定:
想象一个生产车间,这个车间生产一种特殊的零件。
- 零件来源: 零件从外部仓库通过传送带(相当于磁盘读取)运送到车间。
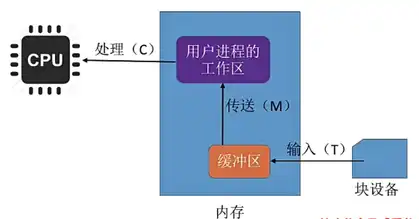
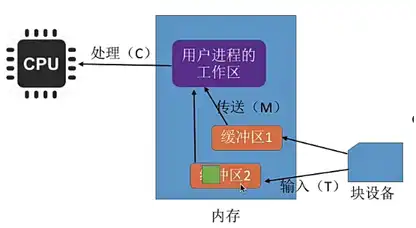
- 加工区: 车间内有一个加工区(相当于 CPU),负责对零件进行加工。
- 缓冲区: 车间内有缓冲区,用来暂存零件,相当于内存中的缓冲区。
- 用户区: 车间内有一个专门的区域,用来存放加工好的零件(相当于用户区)。
生产流程和时间参数:
- T: 传送带将一个零件送到车间的时间(相当于磁盘块读取到缓冲区的时间)。
- M: 将零件从缓冲区搬运到加工区的时间(相当于缓冲区数据传输到用户区的时间)。
- C: 加工区加工一个零件的时间(相当于 CPU 分析数据的时间)。
- n: 需要加工的零件总数。
单缓冲区场景:
- 传送带(T)开始输送第一个零件。
- 零件到达缓冲区。
- 工人(M)将零件搬运到加工区,同时传送带(T)开始输送第二个零件。
- 加工区(C)开始加工第一个零件。
关键点:
- T 和 C 并行: 传送带运输下一个零件和加工区加工当前零件可以同时进行(如果加工时间大于运输时间,则以加工时间为准,反之亦然)。
- 最后一个零件: 最后一个零件完成时,没有下一个零件可以并行处理,所以会单独计算。
单缓冲区公式:
- 每块数据处理时间:
max{C, T} + M(取 C 和 T 中较大值,再加上 M) - 总处理时间:
(n-1) * (max{C, T} + M) + T + M + C(其中T + M是第一个零件的处理时间,C是最后一个零件的处理时间)
理解:
(n-1) * (max{C, T} + M):除了第一个零件,其余每个零件都要经历的 “传送-搬运到加工区-加工”的过程。T + M + C: 第一个零件的传送、搬运以及最后一个零件的加工。