本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com
前言
2025 年 408 大纲在操作系统部分新增了多处理机调度. 值得一提的是 2022 年计组部分新增了多处理器 (或多处理机, multiprocessor) 基本概念, 所以今年算是给多处理机整了个售后.
如果你有能力自己阅读教材, 请务必先阅读下列教材的有关章节. 各大辅导机构也只是糊弄人的教材裁缝, 你自己去读不一定会比他们差, 读教材也并不会耽误你太多时间.
- 计算机操作系统, 西安电子科技大学出版社
- 操作系统概念, 机械工业出版社
- 现代操作系统, 机械工业出版社
- 操作系统——精髓与设计原理, 电子工业出版社
本文将梳理多处理机调度相关的知识点, 不会再补充多处理机的基本概念.
多处理机调度与单处理机调度的区别
在单处理机中, 调度是一维的, 调度程序只需决定接下来运行哪一个进程.
在多处理机中, 调度是二维的, 调度程序必须决定接下来运行哪一个进程, 还需要决定这个进程在哪个 CPU 上运行.
概念: 粒度
粒度用来描述多处理机中进程或线程同步的细致程度. 粒度越细, 进程切换越频繁; 粒度越粗, 进程切换越低频.
概念: 负载平衡 (load balance)
在 SMP 系统中, 总是设法让所有处理器能尽可能的均摊工作, 从而提高并行度, 进而提高效率, 这就是负载平衡.
负载平衡有两种方法:
- 推迁移 (push migration): 操作系统周期性地把进程从负载过高的处理器推到负载较低的处理器.
- 拉迁移 (pull migration): 负载较低的处理器主动从负载较高的处理器上拉取进程.
概念: 处理器亲和性 (affinity)
每个 CPU 内都集成了独立的 Cache. 如果进程频繁的切换 CPU, 会导致 Cache 的命中率大大降低, 所以应该尽量保证进程大部分时间在同一个 CPU 上运行. 即进程具有处理器亲和性, 一些教材也叫做缓存亲和性 (cache affinity).
如果操作系统能保证进程运行在一个处理器子集上, 那么称该系统具有硬亲和性 (hard affinity), 反之则成为软亲和性 (soft affinity). 考虑到亲和性的调度称为亲和调度.
进程分配方式
- 对称多处理系统 (SMP 系统, SMPS) 中的分配方式
- 静态分配方式: 一个进程从开始执行直至完成, 都被固定的分配到一个处理器上去执行.
显然, 静态分配的调度开销小, 但会出现处理器负载不均衡.
- 动态分配方式: 系统中设置一个公共的进程就绪队列, 分配进程时, 可将进程分配到任何一个处理器上.
显然, 动态分配的处理器负载均衡, 但调度开销大.
- 非对称多处理系统 (ASMP 系统, ASMPS) 中的分配方式
ASMPS 多采用主从式 (MasterSlave) 操作系统. OS 的核心部分驻留在一台主机 (Master) 上, 而从机 (Slave) 上只运行用户程序. 主机中维护一个就绪队列, 由主机向从机分配进程.
进程或线程调度方式
- 自调度 (Self-Scheduling) 方式, 或称负载分配 (负载共享, load sharing) 方式
系统中设置一个公共的进程或线程就绪队列, 所有处理机空闲时, 使用单处理机的调度算法从就绪队列中取走进程.
虽然 FCFS 在单处理机中不是一个效率高的调度方式, 但在多处理机中是效率很好的自调度方式.
优点: 处理机利用率高, 负载均衡.
缺点: 就绪队列必须互斥访问, 处理器数目太多时速度会出现瓶颈. 进程在各 CPU 间切换, 亲和性低. 需要合作的线程很难同时运行而被阻塞, 效率下降.
- 成组调度 (群调度, 群集调度, Gang Scheduling) 方式, 或称协同调度 (coscheduling) 方式
成组调度方式把一组特定的线程分配到一组处理器上去执行, 有以下两种方式
a. 面向进程 (应用程序) 平均分配
若有 N 个处理机, M 个进程, 则每个进程有 1/M 个时间去占用 N 个处理机.
b. 面向线程平均分配
若有

优点: 有效减少需要合作的线程的阻塞问题, 此外, 显著的减少了调度开销. 性能优于自调度.
- 专用处理机分配 (Dedicated Processor Assigement) 方式
专门为一个进程分配一组处理机, 每一个线程一个处理机.
这种方式看起来极度浪费处理机时间, 若进程的一个线程被阻塞, 那么该线程的处理机将一直空闲. 但使用这种调度方式也有他的理由:
- 在一个高度并行的系统中,有数十或数百个处理器,每个处理器只占系统总代价的一小部分,处理器利用率不再是衡量有效性或性能的一个重要因素。
- 在一个程序的生命周期中避免进程切换会加快程序的执行速度。
- 动态调度方式
动态调度允许进程动态改变其线程的数目. 操作系统只负责给进程分配处理机, 而进程负责把处理机分配给线程.
操作系统分配处理机时遵循以下原则:
(1)空闲则分配。当一个或多个作业对处理机提出请求时,如果系统中存在空闲的处理机,就将它(们)分配给这个(些)作业,满足作业的请求。
(2)新作业绝对优先。所谓新作业,是指新到达的,还没有获得任何一个处理机的作业。对于多个请求处理机的作业,首先是将处理机分配给新作业,如果系统内已无空闲处理机,则从已分配多个处理机的任何一个作业中收回一个处理机,将其分配给这个新作业。
(3)保持等待。如果一个作业对处理机的请求,系统的任何分配都不能满足,作业便保持未完成状态,直到有处理机空闲,可分配予之使用,或者作业自己取消这个请求。
(4)释放即分配。当作业释放了一个(或多个)处理机时,将为这个(或这些)处理机扫描处理机请求队列,首先为新作业分配处理机,其次按先来先服务(FCFS)原则,将剩余处理机进行分配。
动态调度优于成组调度和专用处理机调度, 但其开销很大.
调度算法评价指标
懒得敲了, 看图:
评价多处理机调度性能的因素有如下几个:
- 任务流时间
把完成任务所需要的时间定义为任务流时间,例如,如图10-6所示,图中有三台处理机P1P3和五个任务T1T5,调度从时间0开始,共运行了7个时间单位。在处理机P1上运行任务T1和T2,分别需要5个和1.5个时间单位;在处理机P2上运行任务T2和T1,分别用了5个和2个时间单位;在处理机P3上运行任务T3、T4和T5,每一个都需要2个时间单位。因此,完成任务T1共需要5+2=7个时间单位,而完成任务T2共需要5+1.5=6.5个时间单位。
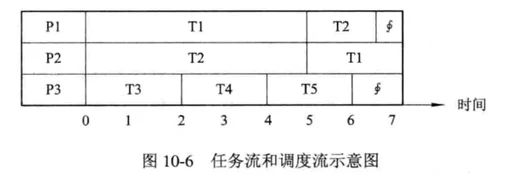
- 调度流时间
在多处理机系统中,任务可以被分配到多个处理机上去运行。一个调度流时间是系统中所有处理机上任务流时间的总和。在如图106所示的例子中,在三台处理机上,调度流时间 = T1流 + T2流 + T3流 + T4流 + T5流 = 7 + 6.5 + 2 + 2 + 2 = 19.5(个时间单位)。
- 平均流时间
平均流时间等于调度流时间除以任务数。平均流时间越小,表示任务占用处理机与存储器等资源的时间越短,这不仅反映了系统资源利用率高,而且还可以降低任务的机时费用。更为重要的是,还可使系统有更充裕的时间处理其它任务,有效地提高了系统的吞吐量。因此,最少平均流时间就是系统吞吐率的一个间接度量参数。
- 处理机利用率
处理机的利用率等于该处理机上任务流之和除以最大有效时间单位,在如图107所示的例子中,最大有效时间单位为7.0,三台处理机P1、P2、P3的空闲时间分别为0.5、0.0和1.0,忙时间分别为6.5、7.0、6.0,它们为各处理机上的任务流之和。由此可以得到P1、P2、P3的处理机利用率分别为0.93、1.00和0.86。处理机平均利用率 = (0.93 + 1.00 + 0.86) ÷ 3 = 0.93。
- 加速比
加速比等于各处理机忙时间之和除以并行工作时间,其中,各处理机忙时间之和,相当于单机工作时间,在上例中为19.5个时间单位;并行工作时间,则相当于从第一个任务开始到最后一个任务结束所用的时间,在上例中为7个时间单位。由此得到加速比为 19.5 ÷ 7 个时间单位。
加速比用于度量多处理机系统的加速程度。处理机台数越多,调度流时间越大,与单机相比其完成任务的速度越快,但是较少的处理机可减少成本。对于给定的任务,占用较少的处理机可腾出更多的处理机,用于其它任务,从而使系统的总体性能得到提高。
- 吞吐率
吞吐率是单位时间(例如每小时)内系统完成的任务数。可以用任务流的最小完成时间度量系统的吞吐率。吞吐率的高低与调度算法有着十分密切的关系,通常具有多项式复杂性的调度算法是一个高效的算法。而具有指数复杂性的调度算法则是一个低效算法。在很多情况下,求解最优调度是NP完全性问题(Nondeterministic Polynomial问题),意味着在最坏情况下求解最优调度是非常困难的。但如果只考虑典型输入情况下的一个合适解,则并不是一个难解的NP问题,因此,可以得到一组并行进程的合适调度。一般所说的优化调度或最优调度,实际上均是指合适调度。


自旋锁 (spin lock) 与智能调度(smart scheduling)
多处理机系统中常常出现争夺资源的情况, 因此多处理机系统中自旋锁的使用非常频繁.
如果某个处理机被分配给了一个线程, 这个线程的自旋锁尚未释放, 时间片到后处理机又被分配给了另一个线程. 而另一个线程因为自旋锁尚未释放, 只能把时间浪费在自旋上.
智能调度方式中, 获得自旋锁的线程会设置一个标志, 只有释放自旋锁时才清除这个标志. 如果调度程序发现了自旋锁标志, 则会给予该线程较多的时间来完成工作并释放自旋锁.